

Just putting this here for anyone else interested in a local UI that runs using Tauri https://tauri.app/ (eg. it doesn’t use electron!)
Thanks for sharing.
How does it compare to LM Studio?
There’s also Alpaca for Linux, and PocketPal for Android
Does it have agent support on Linux?
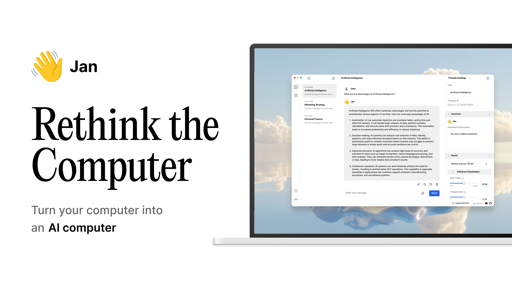
I’ve used this a bit and it’s definitely the slickest OOB local LLM solution I’ve found. Even runs pretty decently on my M1 MacBook.
Is this like ollama, but with more make up?
ollama with less make up (I have only seen screenshots of Ollama, I can’t use it because it doesn’t support Vulkan :X)
Some screenshots, just testing using the Experiment free API on Mistral: https://console.mistral.ai/upgrade/plans



ollama with less make up
Ollama is a CLI tool. It’s distributed as such; there’s no official UI for it.
End users can setup their own frontend clients for ollama (such as OpenWebUI, or LibreWeb), but these are entirely separate projects from Ollama.
Jan ships with a UI, and as far as I can tell there isn’t a CLI component to it. Additionally, Jan uses llama.cpp as it’s backend, just like ollama does. If anything, Jan is ollama with extra make up.
There is an official UI for it now: https://ollama.com/blog/new-app
Looks like it’s only available for macOS and Windows. No wonder I never saw it. Thanks for the correction
Yeah, how exactly does Ollama depend on Vulcan?
Ollama doesn’t depend on Vulkan for its backend. The Vulkan back end is the most widely compatible GPU accelerated back end.
This is to the detriment of it’s users. Ollama works on top of llama.cpp which can run on Vulkan. People have created merge requests for including Vulkan in Ollama. Meta wouldn’t accept it.
Is this why I can’t get llama GPU acceleration on my 7840u with integrated 780m?
I’ve got 96gb of ram, I can share half of that as vram. I know the performance won’t be amazing, but it’s gotta be better than CPU only.
I looked into it once and saw a bunch of people complaining about lack of support, saying it’s an easy fix but had to happen upstream somewhere. I can’t remember what it was, just that I was annoyed 🤷♂️
Edit: accidentally a word
Possibly. Vulkan would be compatible with the system and would be able to take advantage of iGPUs. You’d definintely want to look into whether or not you have any dedicated vRAM thats DDR5 and just use that if possible.
Explanation: LLMs are extremely bound by memory bandwidth. They are essentially giant gigabyte-sized stores of numbers which have to be read from memory and multiplied by a numeric representations of your prompts…for every new word you type in and every word you generate. To do this, these models constantly pull data in and out of [v]RAM. So, while you may have plenty of RAM, and decent amounts of computing power, your 780m probably won’t ever be great for LLMs, even with Vulkan, because you don’t have the memory bandwidth to keep it busy.
roughly, for a small model
- CPU Dual channel DDR4 - 1.7 words per second
- CPU Dual channel DDR5 - 3.5 words per second
- vRAM RTX 1060 - 10+ words per second …
Thanks for the write-up! Specifically I’m running a framework 13 7840U, so it’s ddr5, and that iGPU has no dedicated vram, it shares the main system ram.
I’m not looking for ridiculous performance, right now for small models I’m seeing probably 3 ish words per second. But when I put bigger models in, it starts to get ridiculously slow. I’m fine waiting around, really I’m just playing with it because I can. But that’s entering no fun territory haha
Does ollama have a graphical client now? I have always run it as a background server.
Yes, at least it does on macOS now.
What does this mean?
by make up I assumed he was saying is this more fancy than Ollama, which I don’t think it is, I just like it because it’s similar to LM Studio but without electron
This can’t take file uploads, right?






